
Adoption Is No Longer the Hardest Question
Enterprise AI has entered a new phase. For the past two years, many organizations have been focused on adoption. Leaders wanted more pilots, more copilots, more developer usage, more AI-enabled workflows, and more visible experimentation across the enterprise.
That phase is not over, but a new problem is arriving quickly. The next enterprise AI challenge will not only be whether people use AI. It will be whether the organization can afford, govern, route, measure, and scale AI usage without creating uncontrolled cost, infrastructure pressure, data exposure, and operating complexity.
This is the shift from AI adoption to AI consumption discipline. AI everywhere can sound like progress, but in practice it can become a new form of enterprise sprawl. A company can have AI in development tools, productivity suites, CRM, ERP, service workflows, analytics platforms, security operations, HR systems, procurement tools, and custom applications. Each use case may look reasonable in isolation. Together, they can create a demand curve that finance, architecture, infrastructure, security, and governance teams did not plan for.
AI consumption does not scale like traditional software consumption. Traditional SaaS cost is often linked to seats, modules, usage tiers, storage, or transactions. AI cost can scale with prompts, tokens, context windows, model choice, output length, tool calls, retrieval, agent loops, reasoning time, multimodal inputs, and embedded usage inside vendor platforms.
The question is no longer simply, “Which AI platform should we use?” The better question is, “Which work deserves which level of intelligence, cost, latency, control, and evidence?”
Not Every Problem Deserves the Same AI
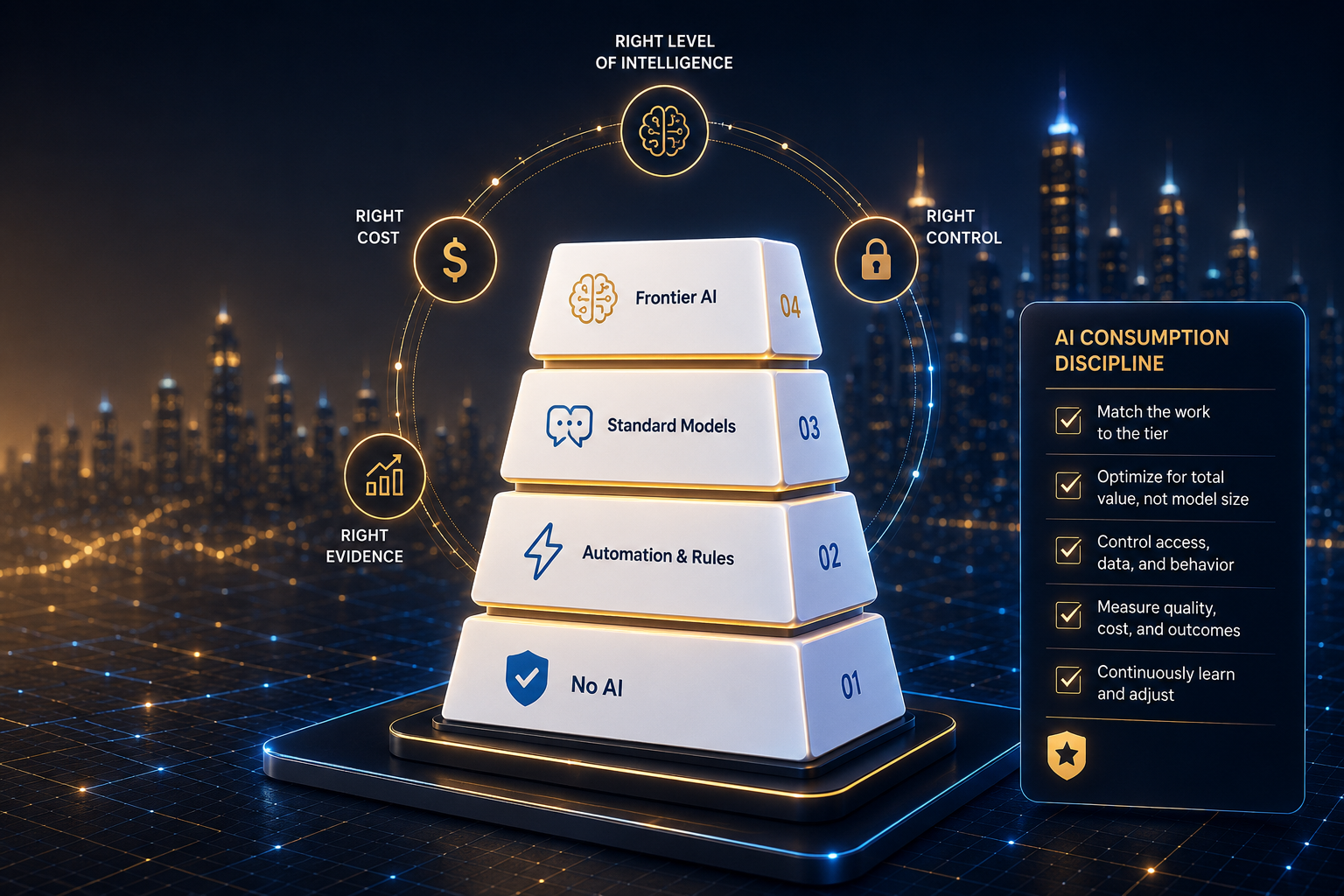
The first discipline is workload placement. Enterprises need a clear model for deciding where AI belongs, where it does not belong, and where different levels of AI should be used.
Some work requires deep reasoning. That may include complex architecture trade-offs, legal interpretation support, high-stakes financial analysis, strategic synthesis, security incident reasoning, and multi-system decision support. These are areas where context, judgment, reasoning depth, and consequence of error matter. They may justify more capable models, stronger review, higher latency tolerance, and higher cost.
Other work needs standard language capability. Drafting, summarization, knowledge retrieval, meeting synthesis, service response support, policy interpretation, and content transformation may benefit from capable language models without always requiring the most expensive reasoning tier.
A third category needs narrow automation. Classification, extraction, routing, validation, translation, reconciliation, structured data enrichment, and repeatable workflow support may be better served by smaller models, cheaper models, constrained prompts, traditional automation patterns, or deterministic workflows.
Then there is work that may not need an LLM at all. Rules, reports, workflow automation, deterministic controls, and traditional analytics may be more reliable, cheaper, faster, and easier to audit. This is not anti-AI. It is pro-architecture.
OpenAI vs Claude vs Gemini Is the Wrong Starting Point
The second discipline is model routing. This is where many practical conversations are now moving. Leaders and teams are asking when they should use OpenAI, Claude, Gemini, a smaller model, an open model, or no model at all.
The answer should not be based on popularity, personal preference, or whichever tool a team experimented with first. Model choice should be based on workload characteristics.
OpenAI may be selected for some workloads because the organization values its reasoning models, structured outputs, tool-calling ecosystem, multimodal capabilities, realtime options, platform maturity, or existing integration path. Claude may be selected where teams value long-context analysis, writing quality, coding workflows, document-heavy reasoning, or agentic development patterns. Gemini may be selected where Google ecosystem integration, multimodal workloads, Vertex AI, search grounding, or cost-efficient Flash-style usage fits the enterprise environment.
But this does not mean every workload should go to one of the most capable frontier models. A high-volume classification flow may need a cheaper model. A structured extraction task may need a smaller model with strict validation. A customer-service routing task may need a narrow model, not a reasoning model. A regulatory control may need deterministic workflow logic, not generative output. A financial approval may need human judgment, regardless of the model used.
The best practice is not “choose the best model.” The best practice is “choose the appropriate model for the work.”
A Practical Workload-Routing Guide
Most enterprises will need a simple routing guide before they need a complex AI platform architecture. Without it, every team will make its own decision. Some will use the most powerful model by default. Some will optimize only for cost. Some will choose the tool already available in their productivity suite. Some will route sensitive work into models without fully understanding data exposure, logging, retention, or evidence requirements.
The goal is not to centralize every decision. The goal is to create a common language for deciding what level of AI is appropriate for the work.
| Workload pattern | Typical AI path | When frontier models may be justified | When cheaper or non-AI paths are better | Control requirement |
|---|---|---|---|---|
| Strategic synthesis and complex risk analysis | Frontier reasoning model with human review | High ambiguity, multiple constraints, high consequence of error | Routine, repetitive, or rules-based analysis | Human approval, prompt/output retention, traceability |
| Long document analysis and policy interpretation | Long-context model or retrieval workflow | Large document sets and nuanced comparison across sources | Repeated document dumping where retrieval or extraction would work | Data classification, source traceability, access controls |
| Coding support and developer workflows | Coding-capable model or agentic development tool | Complex refactoring, test generation, code reasoning | Autonomous changes without review or weak codebase context | Secure SDLC controls, code review, repo access boundaries |
| Service summarization and response support | Standard model, constrained prompts, retrieval | Natural language support with knowledge synthesis | Repetitive low-risk responses that can be templated | Response guardrails, escalation paths, quality monitoring |
| Classification, extraction, routing, translation | Smaller or narrow model | Only if context is complex or errors are costly | Prefer smaller models, deterministic validation, or workflow rules | Accuracy testing, confidence thresholds, exception handling |
| Financial approvals and regulated decisions | Human-led workflow with AI support only | AI may assist analysis, exception detection, or summarization | Do not let generative output become decision authority | Segregation of duties, approval evidence, audit trail |
The Invoice Is Too Late
AI cost must be visible at the level where decisions are made. That means usage by business capability, product, team, workflow, model, vendor, environment, and user group. A CIO cannot manage AI consumption from a monthly invoice alone.
Leaders need to know which use cases are consuming the most tokens, which agents are looping, which workflows use long context, which teams are sending large documents repeatedly, which prompts generate expensive outputs, and which embedded vendor capabilities are increasing cost without measurable business value.
Without that visibility, enterprises will repeat a familiar pattern. The technology gets adopted first. The cost model arrives later. Governance reacts after usage has already spread. That pattern was painful with cloud. It may be more difficult with AI because AI usage is often embedded directly inside the way people work.
AI consumption should not be measured only by activity. Prompt volume is not value. Token usage is not value. Number of copilots is not value. Number of agents deployed is not value. The better measures are cycle time reduced, rework avoided, decisions improved, defects prevented, service resolution accelerated, risk detected earlier, employee capacity released, revenue protected, and controls strengthened.
Controls at the Point of Use
Most organizations will not be able to govern AI consumption through policy documents alone. They need controls embedded into the way AI is consumed. That includes approved model catalogs, workload tiering, routing rules, usage budgets, rate limits, logging, prompt and response retention policies, data classification checks, guardrails, human approval points, exception handling, and vendor usage reporting.
The more AI is embedded into enterprise platforms, the more governance has to move closer to the point of consumption. This is especially important for ERP, CRM, HR, finance, procurement, service, and engineering workflows. AI usage in these domains is not just productivity usage. It can influence decisions, approvals, customer interactions, supplier behavior, financial interpretation, operational prioritization, and control execution.
A casual prompt in a productivity tool may create limited risk. An AI-assisted workflow inside an enterprise system can create operational risk. An agent that reads, reasons, recommends, and acts across systems can create control risk. That is why AI consumption must be connected to access, data, security, risk, compliance, and architecture.
AI Also Consumes Capacity
AI does not only consume budget. It consumes compute, data-center capacity, energy, network throughput, integration capacity, monitoring capability, and human review capacity.
Enterprises may not directly operate the model infrastructure, but they will still feel the constraints through vendor pricing, usage limits, latency, regional availability, data residency options, contract terms, and service reliability. That means architecture teams need to treat AI consumption as part of enterprise capacity planning, not only tool selection.
Infrastructure realism also includes human capacity. A workflow that uses AI to generate more output may still require review, exception handling, quality assurance, model monitoring, audit support, security review, and business approval. If those human controls do not scale with AI usage, the enterprise may simply move the bottleneck from production to validation.
The Operating Model for AI Consumption
AI consumption cannot be owned by one team. The CIO or CTO may own the technology strategy, but business owners determine where AI creates value. Finance and FinOps teams need visibility into consumption, unit economics, budget allocation, and cost leakage. Architecture teams need workload placement, integration patterns, model-routing principles, and reusable design standards.
Security teams need to understand data exposure, access boundaries, prompt and response handling, tool permissions, and agentic actions. Data and AI governance teams need model catalogs, policy rules, data quality standards, evaluation criteria, explainability expectations, and monitoring patterns. Procurement and vendor management teams need commercial terms that reflect actual usage patterns, not only license counts.
That is why AI consumption discipline is not a procurement issue. It is not only a FinOps issue. It is not only an architecture issue. It is not only a governance issue. It is a shared operating model.
AI Needs a Consumption Architecture
AI strategy cannot remain a collection of pilots, subscriptions, copilots, and vendor features. It needs a consumption architecture. That architecture should answer five questions: what work should use AI, what level of AI each workload needs, how usage and value will be measured, what controls govern data and outputs, and how the organization will continuously optimize consumption as adoption grows.
This is where many enterprises will struggle. They will celebrate adoption before they understand consumption. They will add AI to workflows before they define routing. They will negotiate vendor contracts before they understand demand. They will approve copilots before they understand usage economics. They will build agents before they understand control boundaries.
That does not mean organizations should slow down experimentation. It means they need to industrialize learning faster. AI experimentation should now produce more than demos. It should produce workload patterns, cost baselines, routing rules, reusable controls, evidence models, vendor lessons, and operating-model improvements.
AI everywhere is not a strategy. AI where it creates measurable value, at the right cost, with the right controls, is.